
These are quite useful SQL functions which come handy in many cases while analyzing data. In this blog we will see how those work, we will compare them and we will also see couple of use cases.
row_number()
it is a dynamic function which assigns incremental row numbers based on partition and order by expression provided with it.
syntax of row_number() function is given below:
SELECT<columns> ,
ROW_NUMBER() OVER (PARTITION BY expression ORDER BY expression)
FROM table_name;
key words in the function syntax (this key word explanation remains same for all three functions):
OVER – The condition or form in which the row number had to be generated
PARTITION BY – to mention the columns or expression based on which the row number had to be generated. The row number resets to 1 once the partition value changes.
this is a optional clause; that means we can skip writing partition by clause based on our requirements.
ORDER BY – to mention the columns or expression in which order the row number had to be generated.
It makes more sense with below example:
In first example below we have rownumber generated based on user name’s ascending order
project_1=# select *, row_number() over (order by user_name) from users;
user_id | user_name | dept | row_number
---------+-----------+---------+------------
1 | A | HR | 1
2 | A | HR | 2
3 | A | HR | 3
4 | B | admin | 4
5 | B | admin | 5
6 | C | IT | 6
7 | D | academy | 7
(7 rows)In below example we have generated row number based on ascending order of user name and we have partition the row number based on department. we can see the results (marked in RED) as soon as the department changed to admin the counter reset to 1.
project_1=# select *, row_number() over (partition by dept order by user_name) from users order by user_id;
user_id | user_name | dept | row_number
---------+-----------+---------+------------
1 | A | HR | 1
2 | A | HR | 2
3 | A | HR | 3
4 | B | admin | 1
5 | B | admin | 2
6 | C | IT | 1
7 | D | academy | 1
(7 rows)rank()
Similar to row number function we have rank function which generates ranks based on conditions in OVER clause. The rank as the name suggest it dynamically generates ranks that means if there are any clash, it returns same value.
illustration 1 of rank():
in below table we see Ric and David both have scored same scores and they are assigned with same rank that is 3, while the next highest scorer Jane is assigned with rank 5 skipping 1 digit
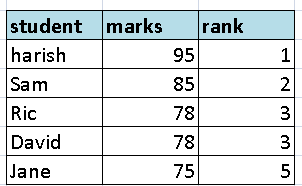
This is exactly how rank() function generates the ranks
syntax: it is similar to that of row number function just the key word changes
SELECT<columns> ,
RANK() OVER (PARTITION BY expression ORDER BY expression)
FROM table_name;
Example: we have used same dataset which has been used for row_number() explanation
project_1=# select *, rank() over (order by user_name desc) from users;
user_id | user_name | dept | rank
---------+-----------+---------+------
7 | D | academy | 1
6 | C | IT | 2
4 | B | admin | 3
5 | B | admin | 3
2 | A | HR | 5
3 | A | HR | 5
1 | A | HR | 5
(7 rows)here we see ranks generated based on descending order of user name. user id 4 and 5 are same value hence both are assigned with rank=3 and next value was 5 which was assigned to remaining rows since the all the values were equal. If we had one more row at the end less than A then rank would have been 8 skipping 2 values.
dense_rank()
Dense rank() work pretty much similar to rank while it has one major difference that is, it does not leave any void if there are any clash; this can be well understood in below illustration.
Illustration 2:
in below table unlike rank() function once there was a clash observed between Ric’s score and David’s score and they were assigned with same rank=3, Jane was assigned with next consecutive number rather than skipping one number.
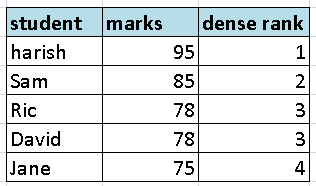
If the difference is not yet clear then, compare this illustration with rank function’s table it makes sense.
Syntax of dense_rank() : there is no change in the syntax, except the function name
SELECT<columns> ,
DENSE_RANK() OVER (PARTITION BY expression ORDER BY expression)
FROM table_name;
Dense rank works same as rank function but only one difference; that is whenever there is clash of ranks, the next rank will be consecutive number; while rank function skips the counter by number of repetitions.
to restate the difference- rank function leaves a void whenever there is a clash, while dense rank does not.
project_1=# select *,dense_rank() over (order by user_name desc) from users;
user_id | user_name | dept | dense_rank
---------+-----------+---------+------------
7 | D | academy | 1
6 | C | IT | 2
4 | B | admin | 3
5 | B | admin | 3
2 | A | HR | 4
3 | A | HR | 4
1 | A | HR | 4
(7 rows)watch below is the video explaining row_number, rank and dense_rank functions with same examples.
Comparison:
below is side by side comparison of all three functions on same expression
project_1=# select *,
dense_rank() over (order by user_name desc),
rank() over (order by user_name desc),
row_number() over (order by user_name desc) from users;
user_id | user_name | dept | dense_rank | rank | row_number
---------+-----------+---------+------------+------+------------
7 | D | academy | 1 | 1 | 1
6 | C | IT | 2 | 2 | 2
4 | B | admin | 3 | 3 | 3
5 | B | admin | 3 | 3 | 4
2 | A | HR | 4 | 5 | 5
3 | A | HR | 4 | 5 | 6
1 | A | HR | 4 | 5 | 7
(7 rows)Practical USE CASES of these functions:
Case1: Nth highest salary/revenue across departments:
Imagine we have a table like below and we need second highest salary from each department and who is getting that
project_1=# select * from sal;
emp_id | emp_name | dept | sal
--------+----------+-------+-------
1 | sam | HR | 30000
2 | ram | HR | 30000
3 | sumana | HR | 35000
4 | karan | HR | 40000
5 | Hari | IT | 30000
6 | suryam | IT | 35000
7 | Ken | IT | 60000
8 | uttara | IT | 35000
9 | aram | DA | 35000
10 | Ric | DA | 60000
11 | David | DA | 40000
12 | Tom | DA | 60000
13 | Jane | DA | 70000
14 | Hari | admin | 40000
15 | Karan | DA | 30000
(15 rows)this can be achieved using dense_rank() function partitioned by department and ordered by salary in ascending order. rank function looks like below
dense_rank() over (partition by dept order by sal) as rnkwe can have this this main query in the with clause and filter the results with rnk=2 and pull the second highest salaries by department. the entire query and the result data set looks something like below.
project_1=# with cte as (select *, dense_rank() over (partition by dept order by sal) as rnk from sal)
project_1-# select emp_id,emp_name,dept,sal from cte where rnk=2;
emp_id | emp_name | dept | sal
--------+----------+------+-------
9 | aram | DA | 35000
3 | sumana | HR | 35000
8 | uttara | IT | 35000
6 | suryam | IT | 35000
(4 rows)Note: since dense_rank() is a dynamic function we can not filter directly. Either we will have use WITH clause to create temp table or we can write a subquery.
below is video explanation of the same case
Case2: Deleting duplicates from the table using row_number:
we see the earlier examples have duplicates in it; user A is with HR dept 3 times and B with admin department entered twice; we generated row_number partitioned by same two columns ;
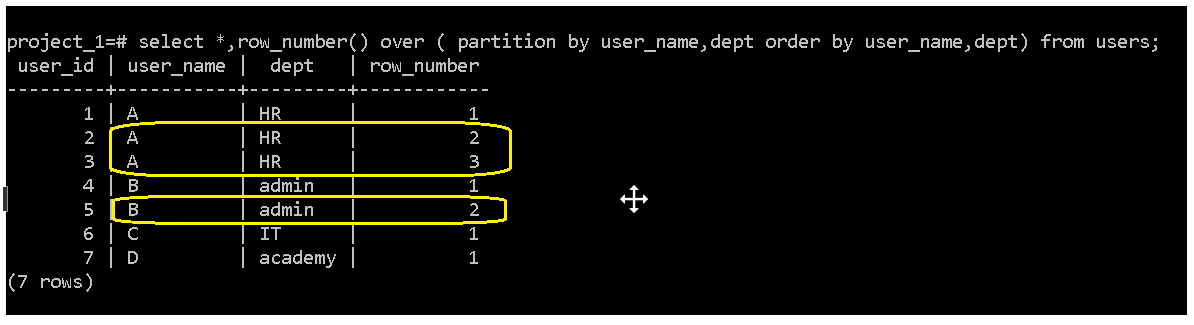
to eliminated those duplicates we can pass the unique IDs or surrogate keys with row_number greater than or equal to 2 into where clause of delete statement; that will help us to keep rows with least SK and clean remaining dupes.
project_1=# delete from users
project_1-# where user_id in (
project_1(# select user_id from(select *,row_number() over (partition by user_name,dept order by user_name,dept) as rnk
project_1(# from users) foo where rnk>=2 );
DELETE 3
project_1=# select * from users;
user_id | user_name | dept
---------+-----------+---------
1 | A | HR
4 | B | admin
6 | C | IT
7 | D | academy
(4 rows)